
Enigma is a data company. It focuses on ingesting large quantities of publicly available databases to extract insights about companies, places, and trends.
As a design co-founder, I was responsible for product management and the design for the product, internal tools, and website.
During my tenure (2011 → 2014), we took the product from a back-of-the-napkin idea to a full-feature public data exploration tool and API, with paying customers.
Public Data Needs Infrastructure
Public data isn't really public
Governments generate enormous amounts data, and are required by law (in the United Sates, at least) to release records if requested by their citizens. Those records are not readily accessible — they are trapped in messy portals, static databases and antiquated formats.
You can't find public data
You can't look for public data sources unless you know what you're looking for. Uncovering the public data about to a company, a place or a government body involves painstaking detective work.
You can't connect the dots
Public data sources cannot talk to each other. A lot of time and energy is spent on testing simple hypotheses that span across datasets.
Designing for Ourselves
Since its inception, Enigma was ingesting thousands of large datasets. Managing, searching, and inspecting them was painful. Off-the-shelf tools did not offer a comprehensive and web-accessible package for us to use. Data Explorer, Enigma's first product, was born out of that need.
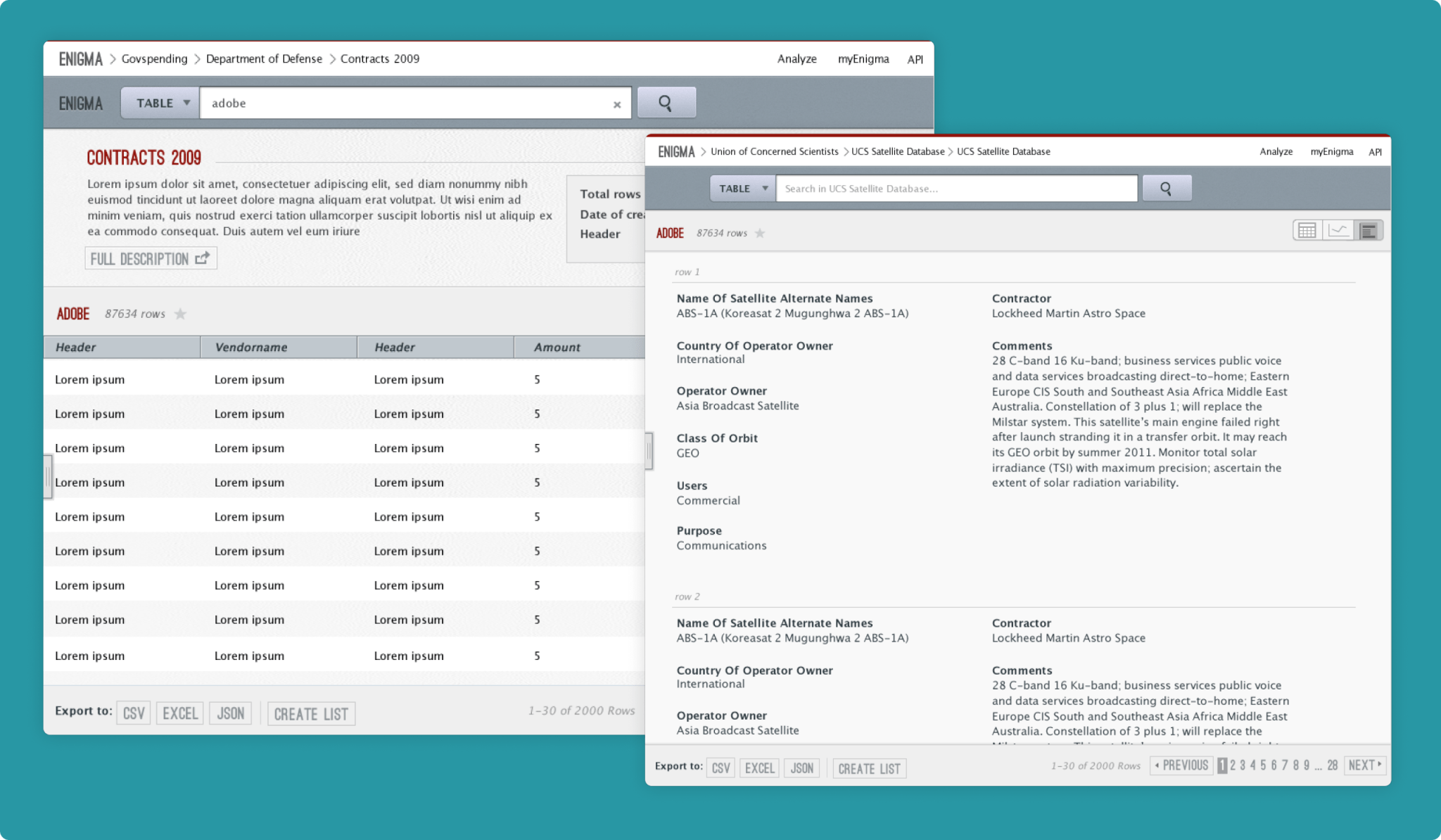
Data Explorer served 3 purposes:
-
Catalog and inspect Enigma's growing collection of datasets
-
Search for datasets and its contents
-
Demonstrating to investors the scale of Enigma's collection and the nature of the problem we set out to solve
Designed and built over a few months, Explorer helped us secure financing to keep gobbling up datasets and defining our business cases, still hazy at the time.
Designing for the Analyst
Having spent time with potential customers and ingesting a greater variety of public datasets, it became apparent that analysts, journalists and academics would value access to the platform. For a subscription fee, Enigma would help to gather insights on a broad range of topics: finance, energy, real estate, agriculture, local politics, etc.
The product was designed to be open-ended, optimizing for its ability to find needles in unsuspected data haystacks.
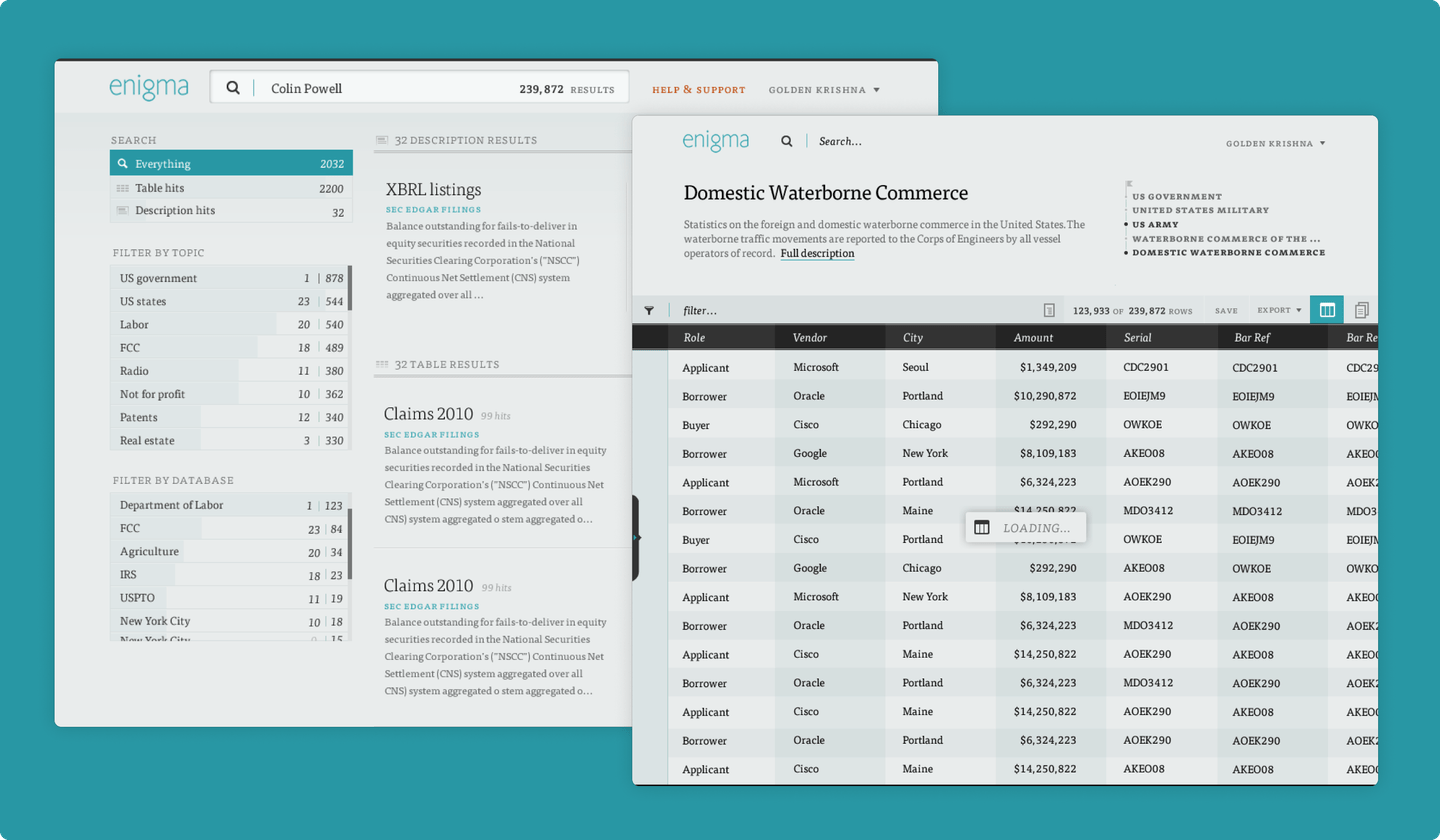
Asking Questions of the Data
At TechCrunch Disrupt in 2013, we demonstrated our vision of a typical workflow on Enigma. By asking simple questions about people, places and companies, one could build a data-rich picture of the world.
This was the Data Explorer's job. Searching through hundreds of millions of rows, testing out hypotheses on the fly, and hopping from dataset to dataset was orders of magnitude easier with Enigma than it was with traditional data research tools.
Data Explorer v1
Data Explorer was released along a Public Data API. Analysts, academics and journalists could discover relevant datasets on Explorer, and subsequently used the API to perform deeper analysis with their own tools.
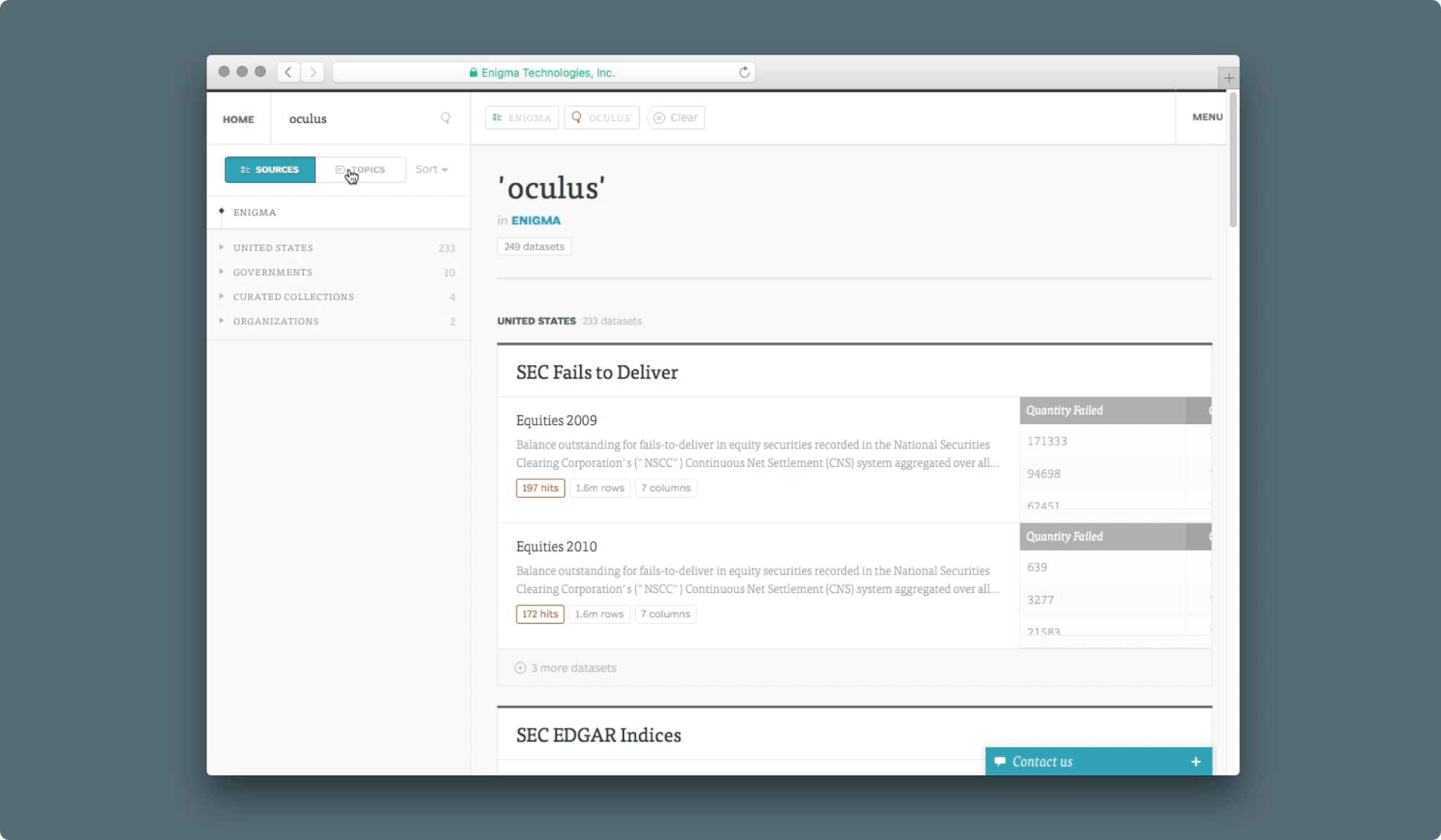
Browse & Search
Datasets in Enigma were organized in a large tree hierarchy, each node (e.g. Department of Energy) with its own description and metadata. Users could browse the collection and pivot into a search without losing context.
Search terms could simultaneously hit table metadata (table hierarchy, tags, description, headers), and data points inside tables. The design challenge was to maintain context as queries got complex (e.g. "search for 'google' in the department of energy's datasets that mention renewables from 2010 to 2015 in California"), while not overwhelming users with redundant results from similar tables.
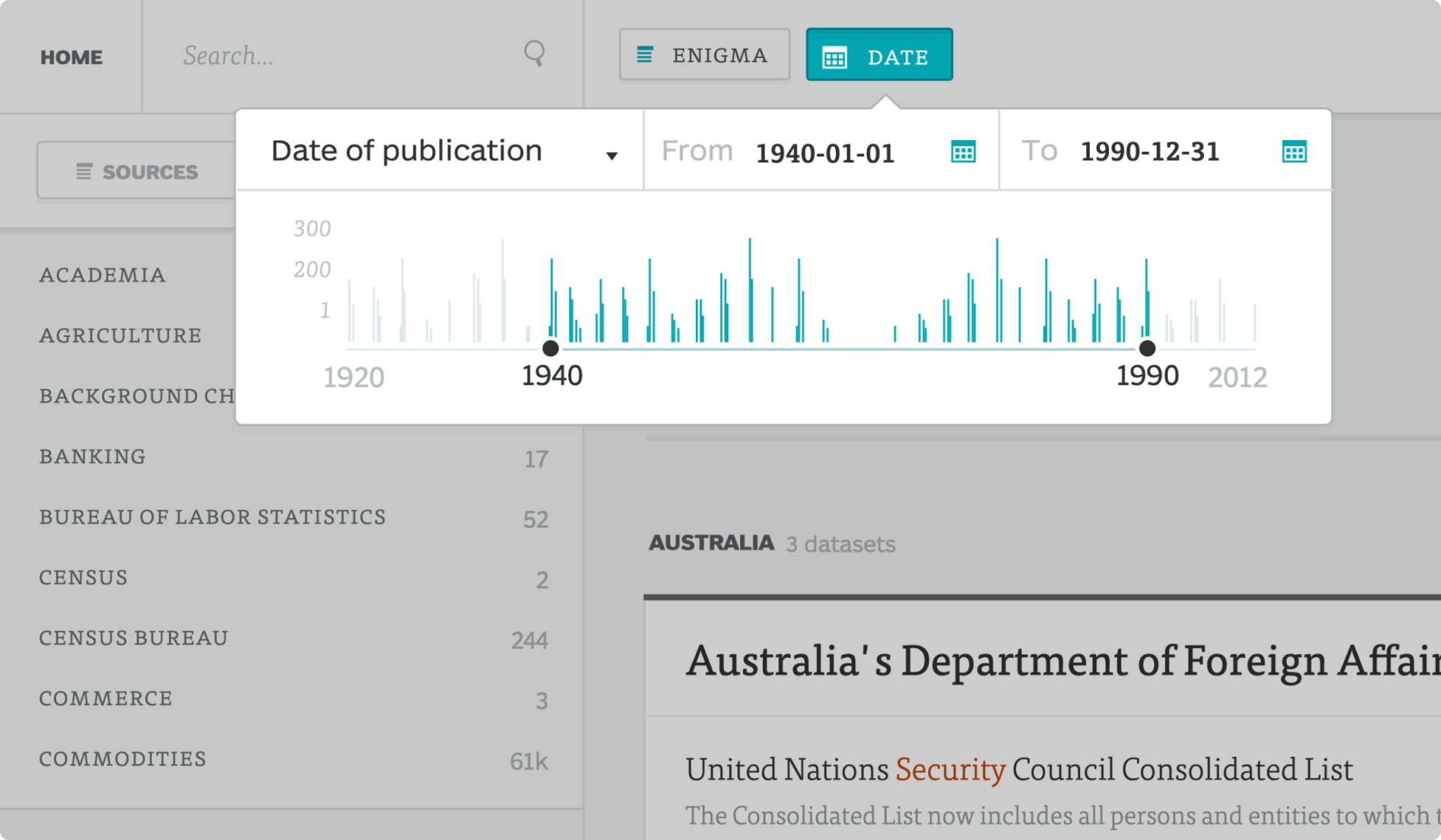
Over time, contextual filters like date and location distribution were added to help cut through the noise.
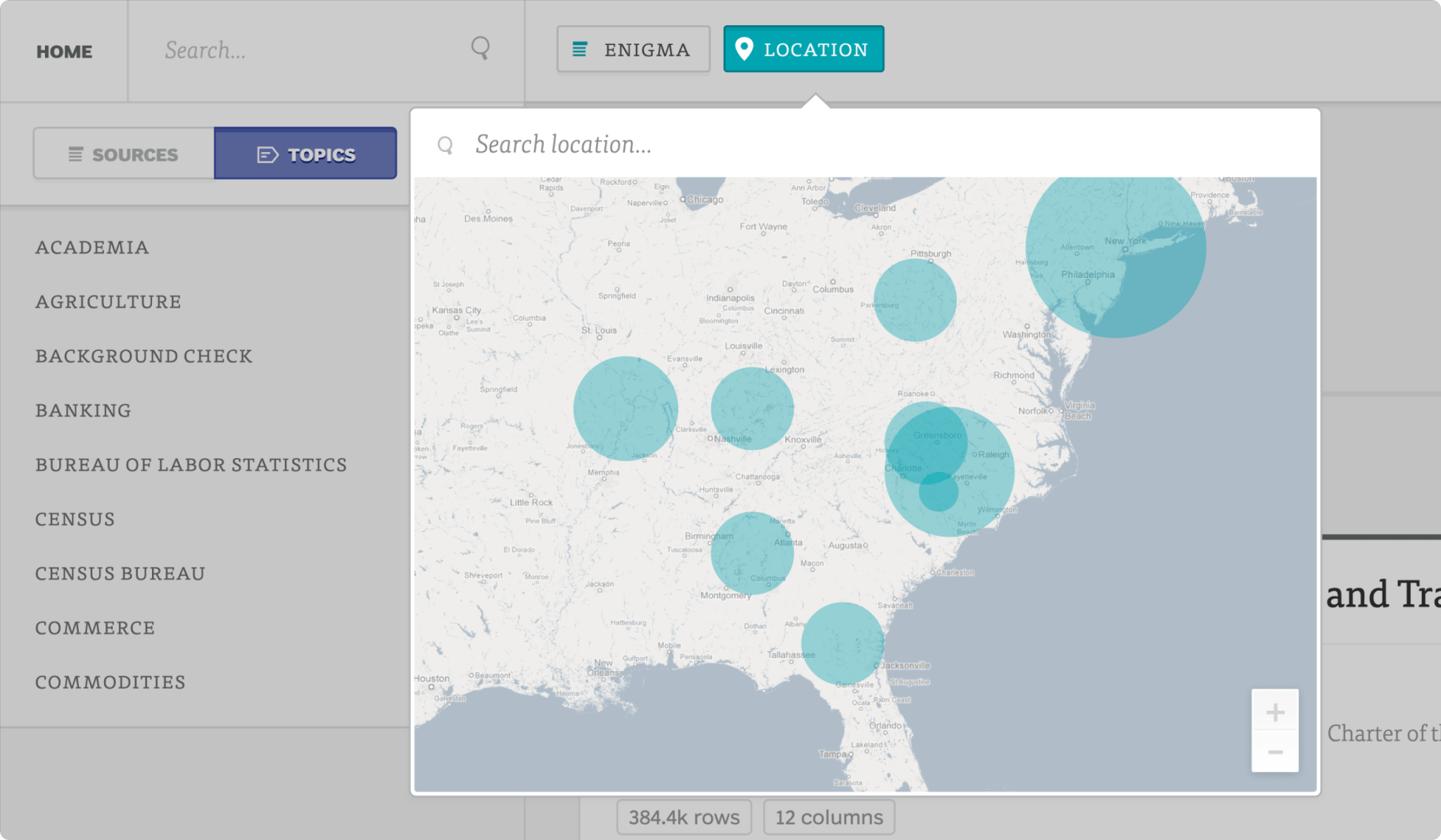
Data Explorer
High performance was a requirement for inspecting large datasets. Data was streamed via websockets to the UI to avoid pagination and curb loading times. Whenever possible, filtering, calculations and pivot searches could be made contextually on individual cells, rows or columns. This made it easy for analysts to look through an individual dataset, shape it to their liking, earmark it for further processing, and move on with their research.
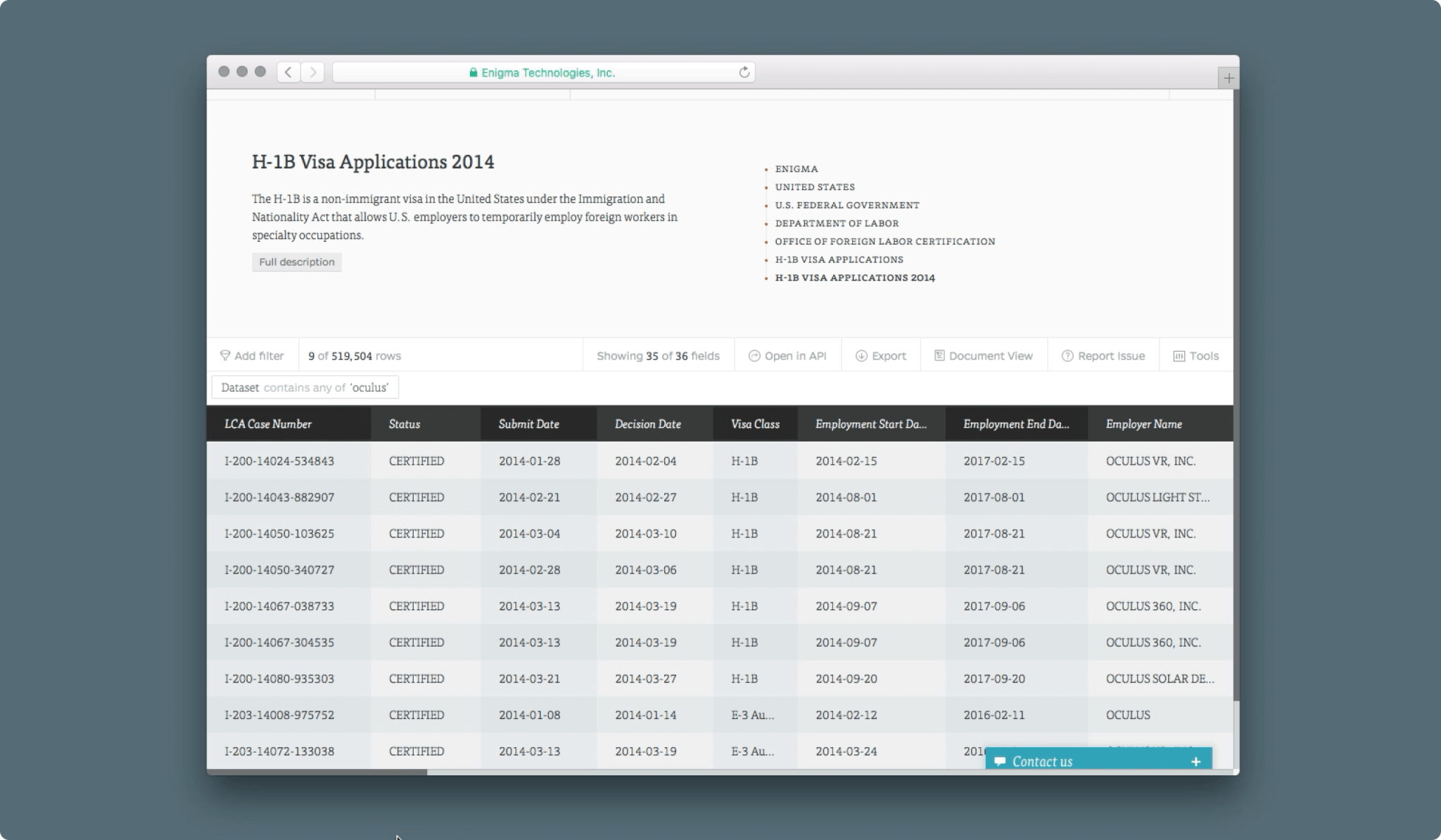
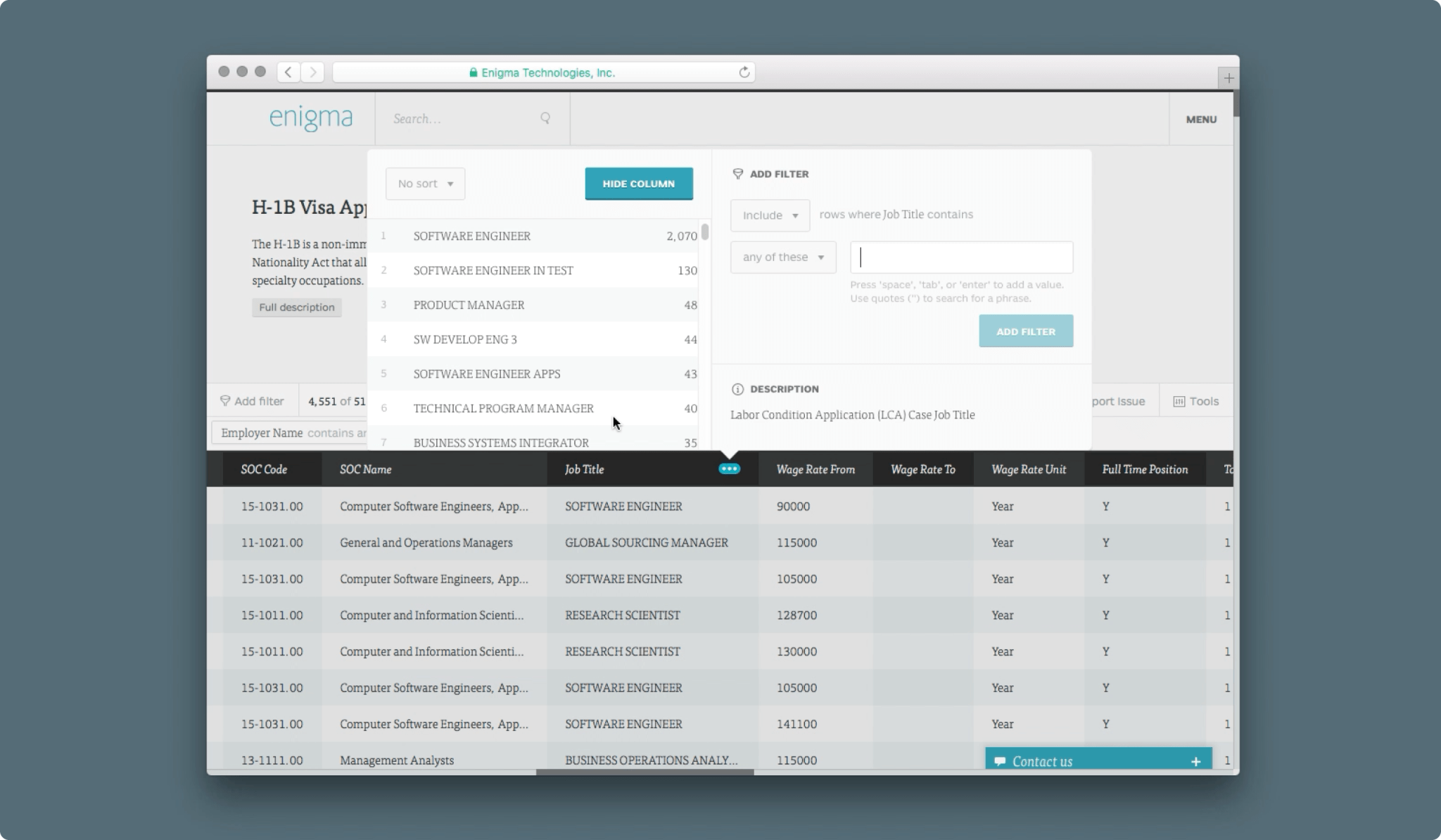
Epilogue
Most of our customers got overwhelmed by the vastness of the data in Public Explorer, in spite of our efforts to categorize and abstract it. Guiding customers with our domain knowledge became a large part of our activity. In effect, we pivoted to a consultancy model and tended to large clients in insurance, energy prospection, pharmaceuticals, etc.
The Data Explorer was retired in 2019 in favor of narrower products with clear value propositions. In retrospect, this was inevitable. Enigma was navigating through uncharted territory at the time; I'm unsure about whether we could have come to that conclusion earlier.
